Documentation
Last updated: March 20th, 2022
- Overview
- Team
- Duration
- Funding
- Components and repositories
- Limitations
- How to contribute to the Catalogue
- How to cite and follow the Catalogue
- Web analytics
- Copyright
- Relevant reading
- Relevant resources
- Acknowledgments
- Navigating the Web Application
Overview
Team
This project is a collaboration between Peter Andorfer and Ksenia Zaytseva of the Austrian Centre for Digital Humanities (ACDH, Vienna) and Greta Franzini of the UCL Centre for Digital Humanities (UCLDH, London). Peter and Ksenia develop the web application while Greta curates the data.
Contributors
Many digital editions in the Catalogue have been added by external contributors, listed here in alphabetical order (those for which we have full names; for some we only have GitHub usernames): Holger Berg, José Calvo, Ulrike Czeitschner, Ricardo Gómez-López, Eglal Henein, Szilvia Maróthy, Arnold Michalowski, Paolo Monella, Martin Anton Müller, Thomas Nehrlich, Frederike Neuber, Clemens Radl, Matthias Reinert, Torsten Schrade, Christian Schwaderer, Werner Stangl, Evina Steinová, Marjam Trautmann, Francesca Tomasi, Gabor Mihaly Toth, Ron van den Branden and Aengus Ward. THANK YOU!
Duration
The Catalogue of Digital Editions began collecting digital editions in 2012. Development on the web application began in the summer of 2016 and kick-started the collaboration. The project will continue for as long as the team's means allow.
Funding
This project receives no funding. Peter Andorfer and Ksenia Zaytseva are supported as ACDH staff, and Greta Franzini's contribution is entirely voluntary.
Components and repositories
The Catalogue of Digital Editions Web Application is made-up of two interacting components, each stored in its own GitHub repository: 1) the data, and 2) the web application to display the data to the user. The two components are connected via a custom script that regularly fetches the latest updates from the data repository and delivers them to the web application.
Data component
The digital editions present in the Catalogue come from numerous sources and their selection follows basic criteria: the electronic texts can be ongoing or complete projects, born-digital editions as well as electronic reproductions of print volumes. They're gathered from aggregators (e.g. Projects using the TEI or DH Commons - Projects), conferences presentations, publications, social media posts, word of mouth, the web, as well as external contributors.
The data is collected across two .csv (Comma Separated Value) files: the
digEds_cat.csv file contains the digital editions, while the
institutions_places_enriched.csv file contains geographical information associated with the
institutions contained in the master file, allowing us to place digital editions on a map.
The data in the Catalogue is being hooked up to the Linked Open Data (LOD) cloud to increase discoverability while supporting semantic integration and knowledge sharing. The linked data vocabularies currently connected to the Catalogue are W3C Basic Geo, FOAF, GeoNames, Data Catalog and Dublin Core Metadata. Institution data also links to DNB (Deutsche Nationalbibliothek) Catalogue IDs.
The data's GitHub repository is: https://github.com/gfranzini/digEds_cat
Web application component
The application is a Django
web framework designed to be simple and pragmatic.
Some fields in the Catalogue's
data file contain decimal numbers as values to measure the degree of compliance of a project to a particular
feature: 0 stands for 'no compliance', 0.5 for 'somewhat/partially compliant', 1 for 'fully compliant'.
Numbers make it easier to run calculations and statistical analyses over the data-set. When fetching data
updates, the web application transforms these values into human-readable information: 0 becomes 'no', 0.5
becomes 'partial/somewhat' and 1 becomes 'yes'. The web application's default view of the Catalogue
data is a searchable table, but it also provides bar and pie charts to better visualise statistical
information (see the Navigation section below).
The web application's GitHub repository is: https://github.com/acdh-oeaw/dig_ed_cat
Limitations
Users might have noticed from the Catalogue that projects from Asian and African countries are underrepresented if not completely absent. The only reason for this large gap in the data is the language barrier. A Japanese project and website can only be correctly catalogued by someone who can read Japanese. Browser plugins to automatically translate webpages exist but we hesitate to use them as any machine-translation errors would go unnoticed and possibly lead to incorrect cataloguing. This is where user contributions become necessary to help provide a global, rather than a Western-centric, picture of digital edition initiatives.
How to contribute to the Catalogue
If you wish to contribute a digital edition to the Catalogue or correct an existing entry, you can do so in one of three ways:
- If you're familiar with GitHub, you can fork the data repository, edit the
.csvfile and create a pull request. - If you're not familiar with GitHub, you can create a GitHub issue with as much information about the edition as possible (see 'Data fields' here). The more information you provide, the sooner the edition will appear in the Catalogue.
- If you'd rather not use GitHub at all, you can fill-in a Google Form at this address: https://goo.gl/forms/4Ya3jwRCBi0VSexx2. Your entry will be moderated and promptly added to the Catalogue.
The project you contribute will be exposed to over 300 libraries in Germany thanks to the Catalogue's integration and syndication in the Datenbank-Infosystem (DBIS).
How to cite and follow the Catalogue
There are two citations for this project. If you wish to cite the data only, please adapt the
following according to your preferred referencing style:
Franzini, G. (2012-) Catalogue of Digital Editions.
If you wish to cite the web application as a whole, please adapt the following:
Franzini, G., Andorfer, P., Zaytseva, K. (2016-) Catalogue of Digital Editions: The Web Application.
You can follow project updates via Twitter and ResearchGate.
Web analytics
We monitor visits to the Catalogue with the Matomo Open Analytics platform (formerly Piwik). This allows us to improve the resource and, to some extent, understand user behaviour on the site while complying to GDPR regulations.
Copyright
As per the Imprint page of this website, the data and code constituting this project are published under a Creative Commons Attribution Share-Alike International 4.0 License (CC-BY-SA 4.0). This means that you are free to reuse all contents as long as you make your copies or adaptations available under the same or a similar license.
Relevant reading
- Franzini, G., Terras, M., Mahony, S. (2019) 'Digital Editions of Text: Surveying User Requirements in the Digital Humanities', Journal on Computing and Cultural Heritage (JOCCH) - Special Issue on Evaluation of Digital Resources, 12(1), pp. 1-23. DOI: 10.1145/3230671
- Franzini, G., Mahony, S., and Terras, M. (2016), 'A Catalogue of Digital Editions', In: Pierazzo, E. and Driscoll, M. J. (eds) Digital Scholarly Editing: Theories and Practices. Cambridge: Open Book Publishers. DOI: 10.11647/OBP.0095.09 [describes an early version of the Catalogue of Digital Editions]
- Krippendorf, K. (2004) Content Analysis: An Introduction to Its Methodology. 2nd edn. Thousand Oaks, CA: Sage.
- Warwick, C., Galina, I., Terras, M., Huntington, P., Pappa, N. (2008) 'The master builders: LAIRAH research on good practice in the construction of digital humanities projects', Literary and Linguistic Computing, 23(3), pp. 383-396. DOI: 10.1093/llc/fqn017
Relevant resources
- Other catalogues:
- The first ever catalogue of digital editions was published and is still maintained by Patrick Sahle under the name Catalog of Scholarly Digital Editions. Sahle's catalogue collects digital editions with a strong critical ("scholarly") component and from which our Catalogue borrows key data definitions.
- In December 2016, a catalogue of Spanish digital editions and texts also appeared on the web and can be accessed here.
- As the name suggests, the RIDE review journal for digital editions and resources publishes peer-reviewed reviews of digital editions in multiple languages.
- The Scholarly Editing journal.
- The multilingual Lexicon of Digital Scholarly Editing brings together field-specific definitions, concepts and terminology found in existing literature.
- The Austrian KONDE - Digital Edition Competence Network.
- correspSearch: Search Scholarly Editions of Letters.
Acknowledgments
We thank Professor Melissa Terras (University of Edinburgh) and Professor Simon Mahony (Beijing Normal University at Zhuhai) for their continuous support and encouragement since the very beginning of this project.
Navigating the Web Application
Browsing the data
This web application provides different ways of browsing the digital editions in the Catalogue,
either as a table or as map and chart visualisations.
Table view
The menu tab Browse the Catalogue lists digital editions in table form and allows users to search for a particular project using one or multiple filters. A bottom pagination indicates the number of data pages present in the Catalogue at any one time (25 digital editions per page), giving users the option to jump between pages. Clicking on a digital edition opens up its corresponding data sheet (Figure 2). Users can also move between projects from the individual data sheets by using the blue back/forward arrows at the top of the screen (Figure 3). A black, round information icon below the project title provides a collapsable column with definitions of each catalogued feature (Figure 4). A red banner is used to inform users of expired project URLs (Figure 5); the banner disappears upon the addition of a working or updated URL.
From the Browse the Catalogue page, users can download all digital editions in the
Catalogue at any one time as .csv, rdf/xml and n3.
In addition, the menu tab Get the Data gives the user the option of downloading the data as a BibTeX file, which can be imported into bibliographic managers such as Zotero for citation purposes. The project's API is also available under Get the Data.

Figure 1. Pagination at the bottom of the main Browse the Catalogue view allows users to jump between data pages in the Catalogue.
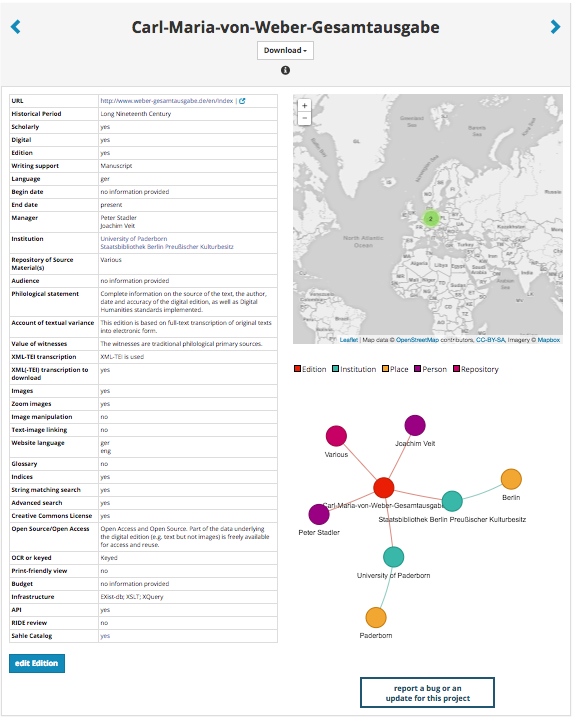
Figure 2. Example data sheet of a digital edition.

Figure 3. Blue back/forward arrows placed at each side of the project title allow users to move between digital editions.
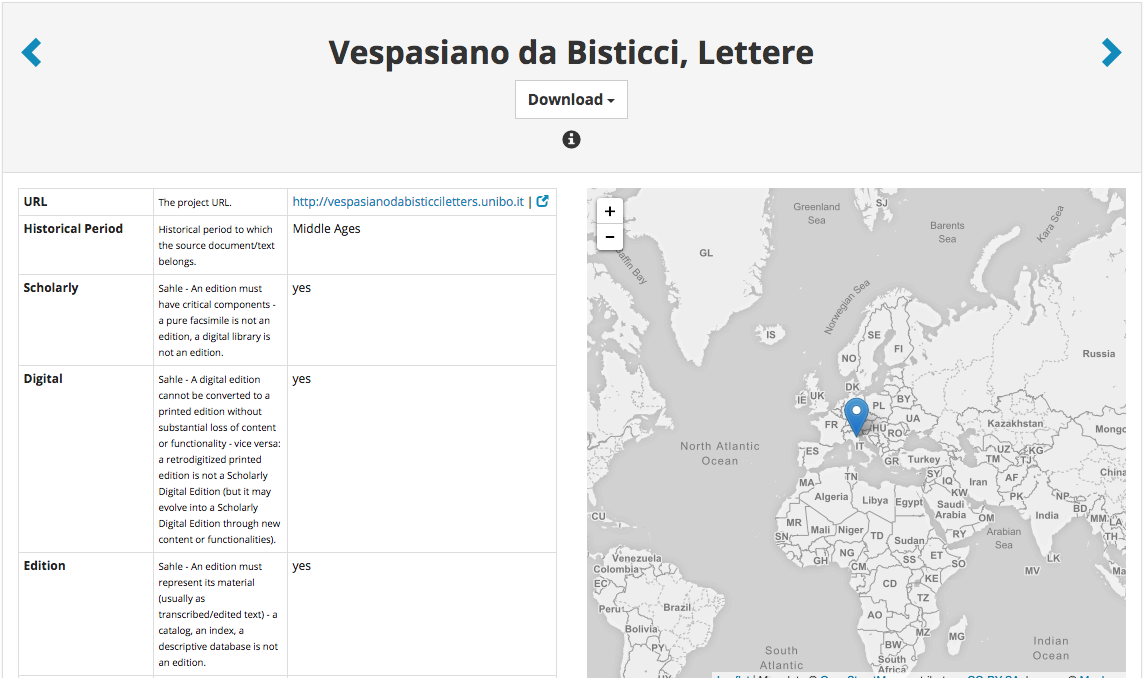
Figure 4. The black circular information icon below the project title reveals a collapsable column (second column in this image) with definitions of each catalogued feature.

Figure 5. A red banner notifies the user of an expired project URL.
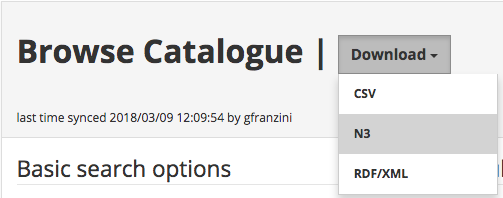
Figure 6. The bulk-download button on the Browse the Catalogue page allows users to
download the most recent data in the Catalogue as .csv,
rdf/xml and n3 files.